Diving Deeper: Navigating AI in Driving Assistance
Milan Spiridonov, 25th November 2024
Welcome back to my journey through the AI For Society minor! Over the past month, I've delved deeper into my personal challenge of creating an AI Driving Assistant. This post will cover the progress I've made, the challenges I've faced, and the insights gained from discussing the project with various consultants.
Revisiting the Project Scope
In the wishful thinking of the project's early stages, I envisioned an AI system that would seamlessly integrate into a vehicle, providing continuous assistance throughout a whole journey. However, after a couple of meetings with consultants, I am now more humble in my vision, as I better understand how important it is balance the technical side with user experience and the various safety considerations that would come with such a project.
My initial plan for the project was to just have an AI system that runs continually, analyzing the environment and making decisions in place of the driver, or in my wilder dreams - be able to fully control the car by itself. Technically, the idea might be executable in a simulated environment, but in reality, the idea of being in a car that's able to, at all times, take control instead of the driver sends shivers down my spine. It's hard to imagine genuinely (and happily) entrusting your life to a machine that has nothing to lose, and is maybe drunk on cheating the system for extra reward points.
Balancing AI Intervention and Driver Autonomy
One of the most notable conversations I had was with Mariëlle our Psychology Consultant. Although short, we got to cover a lot of ground, namely the effects such a One of the most insightful discussions I had was with Mariëlle, our Psychology Consultant. We talked extensively about the importance of the AI not becoming overly intrusive, which could lead to driver frustration or over-reliance on the system.
User Experience
Mariëlle emphasized that driving is not just about getting from point A to B; it's an experience that many people enjoy. The sense of control, the thrill of the open road, and even the meditative state some achieve while driving are all integral parts of this experience. An AI that aggressively takes control can detract from this enjoyment.
We discussed how existing driver-assistance technologies, like adaptive cruise control and lane-keeping assist, sometimes overstep their bounds. They can feel unnatural or even jarring, especially when they make unexpected corrections. Our goal is to create an AI assistant that enhances the driving experience without compromising the driver's sense of control.
Trust and Reliance
We delved into the psychology of trust in AI systems. An overactive assistant might cause drivers to become passive, reducing their attentiveness and potentially leading to unsafe situations. There's also the risk of drivers becoming too dependent on the AI, assuming it will handle everything, which can result in slower reaction times when human intervention is suddenly required.
Mariëlle pointed out the phenomenon of "automation complacency," where users of automated systems become less vigilant. In the context of driving, this could be dangerous. To mitigate this, we need to design the AI assistant to keep drivers engaged and attentive, perhaps by providing alerts that require acknowledgment or by limiting the AI's interventions to specific scenarios.
Configurability
In order to address the differences of expected UX between users, I could allow for different levels of AI assistance, so that drivers can adjust the amount of intervention they observe.
A sample list of options for this would be:
- "No Assistance"
- "Recommendations Only"
- "Emergency Interventions Only"
- "Moderate Assistance"
- "Total Assistance"
And in order to address personal behavioral differences, habits and driving styles, I could also implement some sort of data collection (locally), so that the AI model can further learn what are the drivers' preferences (e.g preferred car distance, slow & steady braking vs more aggressive breaking, overtaking aggression, etc…)
Legal Considerations
Another aspect that requires much consideration, is the fact that this system will be at minimum used as an advisor for drivers and how they act on public roads, and in more extreme cases - can have as much control as the actual driver of the car.
At face value, this sounds like a liability nightmare for multiple reasons:
- In the case of an accident, who's to blame?
- Is it the AI system itself (hence all real parties are free from repercussions)?
- Is the developers of the AI system?
- Is it the driver, since they allowed for the bad judgement of the AI to be executed?
- Is it the driver, since they're using a (most likely unregulated) AI system to augment their vehicle's behavior?
- Is the fault ultimately shared between the driver and the AI system (or AI system developer)?
- In the case of a traffic violation, who's to blame? (all of the above possibilities apply here as well)
- How could such a system even be distributed?
- If it were baked-in into vehicles, then there has to be some regulatory hell, that makes sure only the best & most thoroughly-tested solutions can enter the market (see self-driving-vehicles-5-are-self-driving-vehicles-allowed-public-roads for further explanation on Dutch laws)
- If a roundabout method were to be employed, where users only receive the necessary hardware + software, and they need install the solution themselves (thus in a way implementing the AI Assistant themselves), am I void of any future liability?
- If the system were more limited (i.e only level 2 automation), would the regulations be less strict? - Something similar can be seen with comma.ai's
openpilot, which mostly adds (or improves) automation level 2 systems in cars, simply improving the safety of drivers, without claiming much control and responsibility. (Even in their case, although active for about 8 years, there are some uncertainties, and they advice doing your own research before using their product).
- What about insurance? - If having such a system installed doesn't affect one's policy, then I don't know what would - many insurers take into consideration if a car is shared between multiple persons, so I doubt they wouldn't care much about an AI system sometimes making decisions in place of one of their clients.
Liability Issues
A big question that keeps popping up is: who is responsible if something goes wrong? I looked into how companies like comma.ai navigate these challenges by focusing on user-installed hardware.
Here are some considerations:
- Shared Liability: Figuring out how liability is divided between the driver and the AI system.
- User Agreements: I'll need to draft clear terms of service and disclaimers to inform users of their responsibilities.
- Insurance Implications: It's crucial to investigate how insurance companies view AI-assisted driving and what coverage would be available.
Driver aid
Since I plan on the models living on board a small computer housed somewhere in the car, where the driver themselves will install, this implementation can easily be called "driver aid", as it ultimately serves the same purposes as cruise control or lane assist, or any similar aid. In these cases, liability is normally attributed to the driver, i.e if your cruise control hits somebody, you'd be at fault for not canceling it/reacting. Comma.ai allow users to download the source code for their product and include the following statement in their readme:
“THIS IS ALPHA QUALITY SOFTWARE FOR RESEARCH PURPOSES ONLY. THIS IS NOT A PRODUCT. YOU ARE RESPONSIBLE FOR COMPLYING WITH LOCAL LAWS AND REGULATIONS. NO WARRANTY EXPRESSED OR IMPLIED.”
More commentary on this approach can be seen here, as well as some arguments for extended liability and the potential for lawsuits, especially since there's nowhere users can explicitly agree that they're taking full accountability.
I've never seen this scenario in my life
Now for the interesting part - I also got to do some coding & even go beyond the regression model approach I had taken.
While I was pretty happy with the surface-level performance of the model I had trained last month, there certainly were issues with it. Since my training data was fairly limited (I had collected about 4 minutes of gameplay (~14k rows)), the model was able to react only in situations it had already seen (i.e I had recorded).
While playing around, in my initial excitement, I let "my" car get too close to the car in front of it, but apparently due to my dataset not containing data for occasions where there's 2 meters of distance between the two cars, the AI model decided that the most appropriate move is to floor the gas, directly ramming into the car in front of it.
While there might be a way to configure the model in-training to make up for the missing data, this accident was enough for me to happily say I'm done with regression for this case, and try my hands at Reinforcement Learning.
Implementing Reinforcement Learning
Reinforcement Learning is fundamentally different from regression or other supervised approaches because the model learns by interacting with an environment and receiving feedback in the form of rewards and punishments.
This approach was also very new to me, so before doing anything too crazy, I decided to do some reading on the topic, looking at what-is-reinforcement-learning, where we see the basics of implementing reinforcement learning using OpenAI's Gym library and a pre-defined environment. While this tutorial was very useful to understand the basics, loading already existing environments wouldn't cut it for our case.
From there, I went on to learn that this library also supports creating custom environments (see here for one of the tutorials I used). Following the tutorial's example, I first defined my custom environment's observation & action spaces.
Observation space is what we "show" to the model, or what it "sees" Action space is what the model outputs
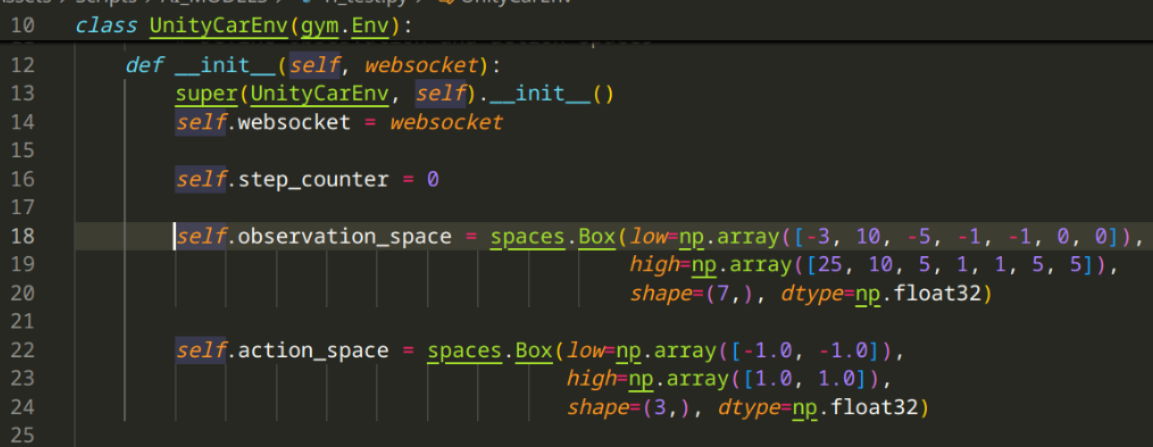
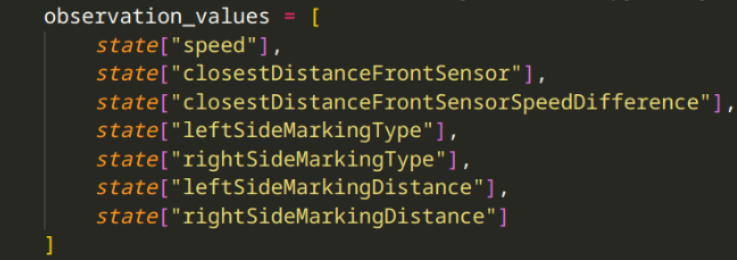
Where the observation space holds (at object low) the minimum (, at at object high) the maximum values possible for the different values, and the shape object - I'm not entirely sure why we use it like so, but the number is the amount of dimensions. Below you can see the fields I'm adding to the observation space:
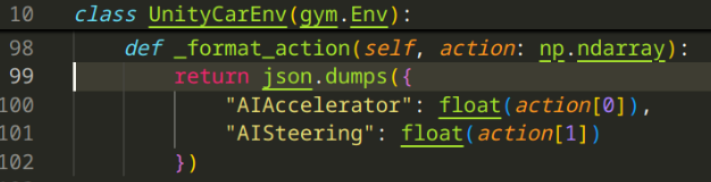
And the action space only contains Accelerator & Steering Direction:
After defining the spaces, I had to implement the reset & step methods:
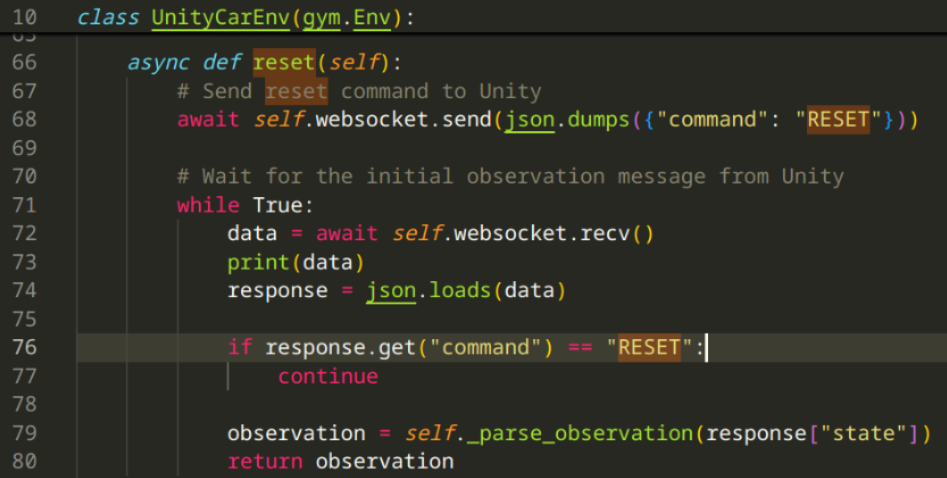
Might look out of place, but in my case, only the python script sends
RESETcommand, and the Unity environment sendsdone(seestepimplementation below). What this does, if reset is called (and that only happens when unity environment says so /processed by step/), we sendresetcommand to Unity, which resets the scene, and wait for the next frame's observation (while explaining this, I'm starting to realize that the method might be a bit unnecessary)
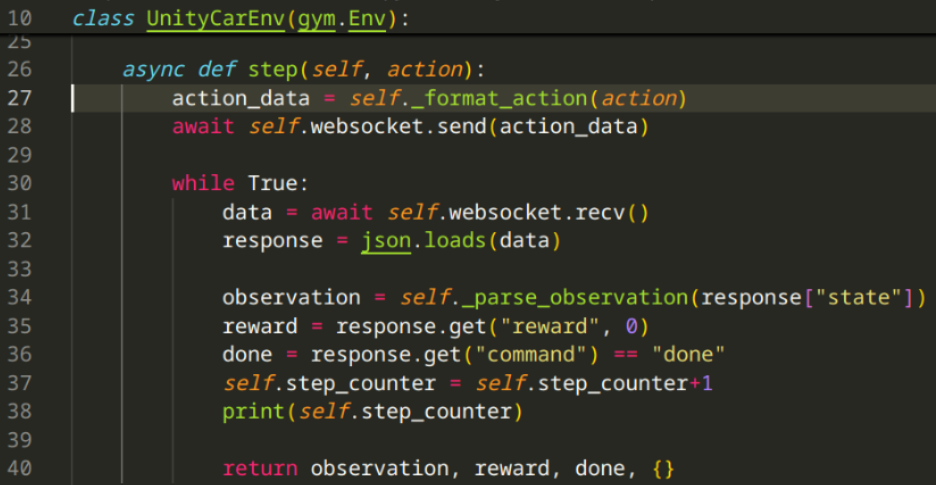
Here we receive the
actionpredicted by the model and send it to the Unity environment, awaiting a response from the environment, parsing it after it's received and returning it, for use in next prediction
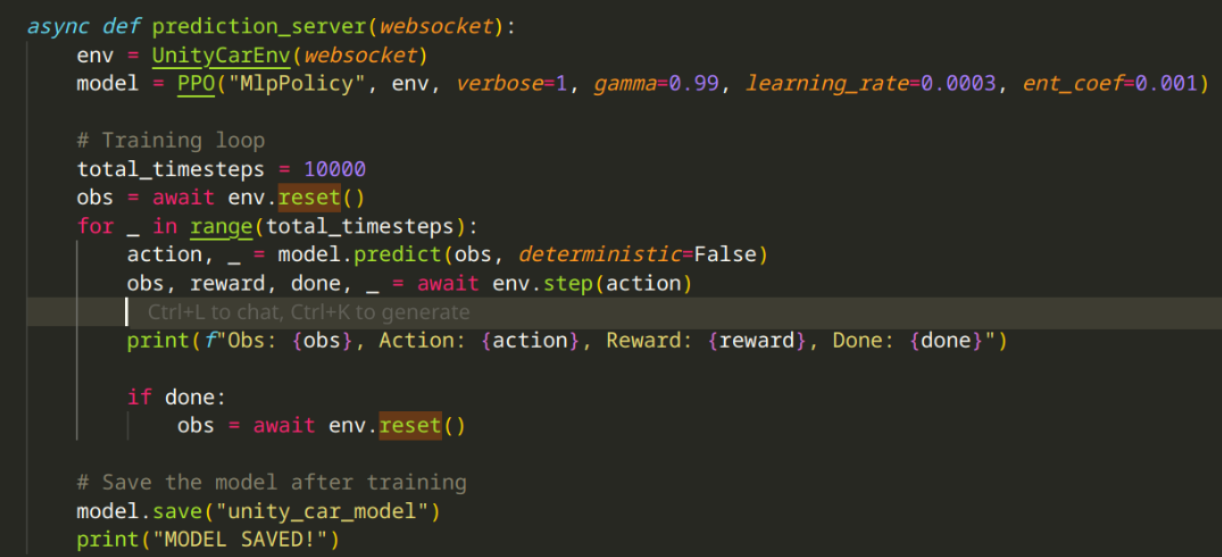
If the last couple of paragraphs didn't make much sense, this function should shine some more light on what's happening. You can see how at the beginning of the training script (post-env setup), we cause a reset (so Unity is prepared) and get the initial observation state, and after that we enter into the training loop. We pass the first observation to
model.predict, which will give usactionvalues, which we can pass to step (where we process & send them to Unity), if we get thedonecommand from Unity, we cause another reset (happens whenever the car has moved too much backwards).
In order to handle this properly, I had to modify my Unity code a bit as well.
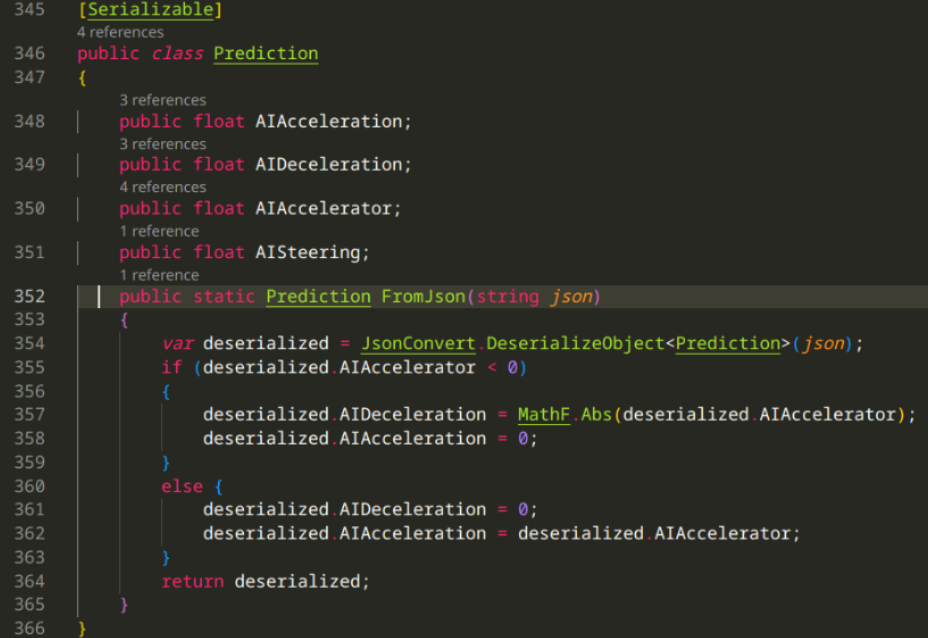
First I needed to update the Prediction model, especially since I moved on to Accelerator ∈ [-1,1] value in the AI model, instead of both acceleration & deceleration.
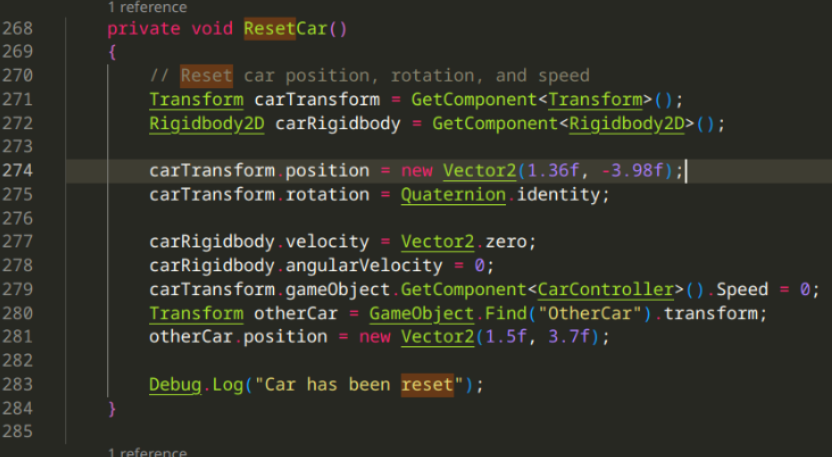
Also implemented a very non-hard-coded reset scene method:
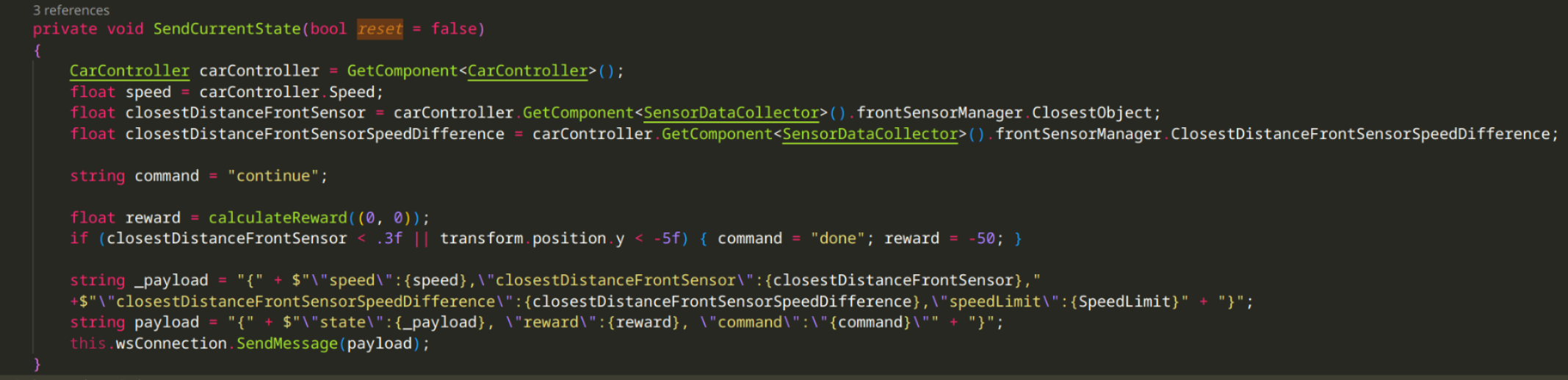
and a SendCurrentState method, which collects all sensor values, prepares inputs, requests reward calculation & sends it as json to the python WS server:
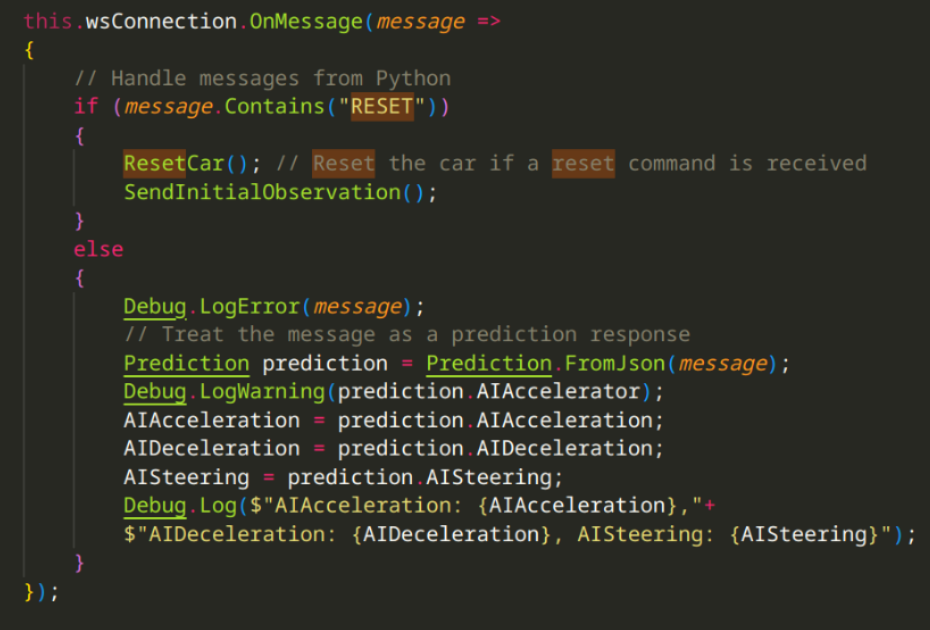
, and handle the messages received from the AI model:
LEARN, MACHINE, LEARN!!!
Having prepared everything, I was ready to start considering the different technical aspects that would go into training the model:
- Hyper-parameters: In our case, I had to select values for
gamma- (also known as Discount Factor) determines how much the agent prioritizes immediate rewards vs long-term rewards. Where this value is0, the agent will do it's best to get as much rewards in the short term as possible, and while it's1, the agent will do it's best to get more rewards in the long term (potentially sacrificing immediate positive feedback). Since this is a float (in the range ∈ [0.00, 1.00]), it's important to find a balanced value, which allows the agent to both use a long-term strategy, but also properly respond to feedback given to it.learning_rate- determines how fast the model's weights are updated during training, with higher values leading to the model's learning, having the value lower would allow for more precise updates, but slowing down the training process (not in amount of steps per session, but in terms of effectiveness per X amount of steps). Being able to properly balance this value would lead to effective training sessions. Jacco advised me to keep this value at around0.0003, and to adjust as needed when experimenting.ent_coef- (also known as Entropy Coefficient) is used to encourage exploration during training. It introduces a penalty to the loss function based on the entropy of the policy, which I'm still not entirely sure what it means, but it should affect the randomness of actions selected throughout the session. A higherent_coefwould promote the agent exploring a wider range of actions, which would be beneficial in complex scenarios (like an AI driving assistant), while a lower would not incentivize as much exploration, but rather lead the agent to using already explored actions, which would lower randomness & increase predictability. Since our models will be used in fairly complex (yet too-important-to-fail) scenarios, it's important to find a setting which allows the model to prepare for a variety of situations, while also not allowing it to be too sporadic.
- Amount of timesteps - this value would define how many actions the model must predict throughout the training session. Since we're running in a synthetic environment (game engine), we have somewhat of a constraint which wouldn't really be the case in the real world - games operate in frames (or ticks), and in this specific case - I'm running the physics calculations @60fps (or 60 physics updates per second). This means I can request a prediction 60 times per second, or, the AI model must make a step once every 16ms. With this knowledge, we can calculate that to have the AI Model drive our car for 1 minute, we'll need to run 3600 steps (or predictions).
I decided to initially train a model for 100k steps, which amounts to ~27 minutes. From there, I could save the model & further train it:
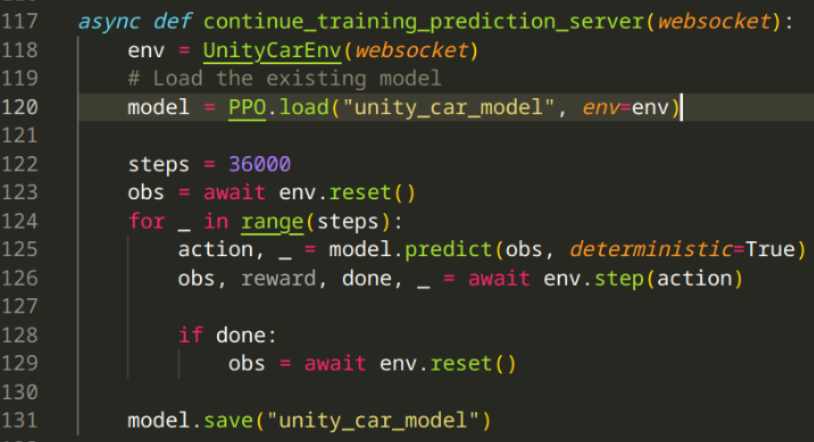
- The
deterministicparameter defines whether the model's action selection is fixed or variable - the model will always return the same output for the same input. This option is recommended for whenever we're expecting our model to act in a predictable manner. If we were to passfalsefor this parameter, the model will introduce some randomness to the actions, where we might get different outputs for the same inputs. This would be calledStochastic Action Selection, and is preferred whenever we need more exploration during our training session.
Up until this point, I didn't get to have the model reach any valuable performance levels, but I plan on changing some values and simplifying the observation space next month.
Conclusion
While I wasn't able to reach satisfactory results from the model, I now have everything setup for me to continue refining the parameters & inputs/outputs, until the training works out.
For the next month, I plan on:
- implementing the model splitting (tiering), so that I can train simplified models
- have at least of the models implemented and working properly
- add road marking & respective sensors, so we can potentially train a model for
lane assistor something along those lines - adding support for multiple models input, so that we could later combine them
- figure out if I can improve the way I currently handle rewards and model outputs, since the model often gives unrealistic values (and doesn't stop doing so), like only giving
0.074as accelerator input, without even trying to increase the value.
As for the societal issues, I plan on:
- doing more research on the legal front and discussing it with one of our legal consultants
- looking into the potential future impacts such a system might have on a societal basis
My dearest of fans, thank you for your time!